In the audio world, there are many applications in which we are recording a vocal track, or communicating vocally in real-time. In general, it is important that these recordings or communications are smooth and noise-free for the most pleasurable user experience. This article will specifically focus on the improvement of vocal tracks with de-essing.
De-essing in digital signal processing is any technique which reduces sibilant frequencies in a given audio signal. Sibilant frequencies are frequencies which are created by unvoiced vocal enunciations such as ‘s’, ‘sh’, and ‘z’. In certain audio applications the hissing sound created by sibilant frequencies can be unappealing, and so it can be beneficial to reduce or remove the problematic frequencies to attain a smoother sounding audio signal.
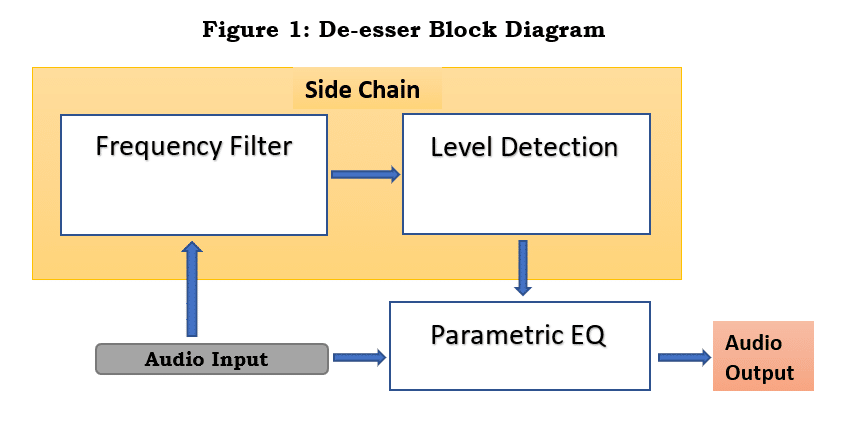
There are many different ways to implement a de-essing algorithm. Most implementations take advantage of a side-chain which can detect the sibilant frequencies. When the detection conditions for sibilance are met, the side-chain sends a control signal to the equalization block in the main signal path. The main signal path usually contains a compression or equalization block which essentially applies negative gain selectively to the signal, so that sibilance is mitigated while the remaining parts of the signal are unchanged.