The overarching goal of any speech enhancement algorithm is to estimate the desired speech signal from the noisy speech signal. During supervised learning for Deep Neural Network (DNN) Speech Enhancement, the desired speech signal is available as reference to train the network. Early research directly used this signal to train the network by minimizing the mean square error (MSE) between the DNN output and the desired signal. This temporal mapping becomes too dependent on the noise characteristics used during the learning stage.
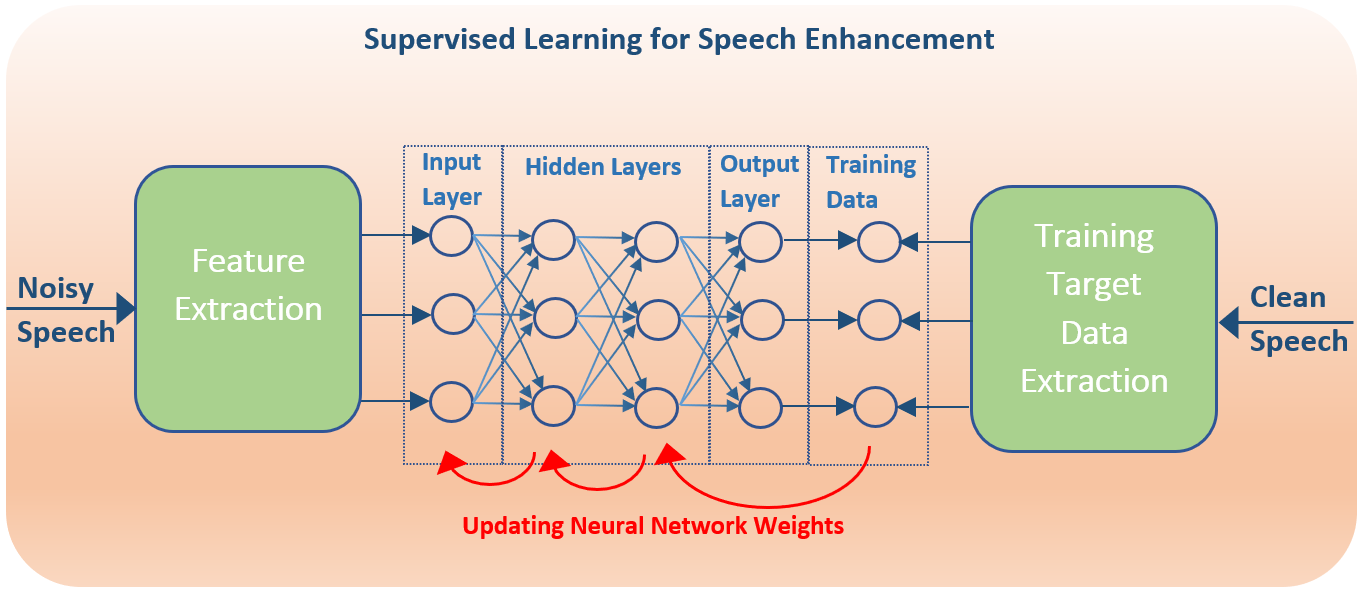
Multi-layered networks of time domain signals end up representing the signal in the transform-domain. Therefore, to reduce complexity of the neural network, the signal can be transformed (to the Fourier domain, Mel-domain or Gammatone domain) and domain coefficients can serve as the input to the DNN. The gain function performing the speech enhancement can also be performed in the transform-domain. In this case, the training target can be what is termed the Ideal Ratio Mask (IRM). For each time – frequency (transform domain) unit the ideal ratio of the speech to noise is determined from the known clean speech and noise data signals, as shown in the equation below:
}^2}{{S(t,f)}^2+{N(t,f)}^2})}^\beta")
This is analogous to the Wiener filter design for the optimal estimator of the speech signal. As indicated by the denominator this mask does assume the additive noise model.