Uniform circular array uncorrelated noise SNR improvements with delay and sum beamformer. The use of circular array topologies for beamforming as opposed to linear arrays allows the array to remove the  look direction ambiguities whilst keeping the advantages of beamforming. Conventional derivations for the signal to noise ratio improvements using delay and sum beamformer is that you get
look direction ambiguities whilst keeping the advantages of beamforming. Conventional derivations for the signal to noise ratio improvements using delay and sum beamformer is that you get  gain for every doubling of the number of microphones being deployed. This holds
gain for every doubling of the number of microphones being deployed. This holds  the noise is not directional or in other words, uncorrelated. We derive the expected SNR gains for uncorrelated noise on UCA microphones and show that it is the same as that for the ULA. Consider a far field source impinging N UCA microphones as shown in Figure 1:
the noise is not directional or in other words, uncorrelated. We derive the expected SNR gains for uncorrelated noise on UCA microphones and show that it is the same as that for the ULA. Consider a far field source impinging N UCA microphones as shown in Figure 1:
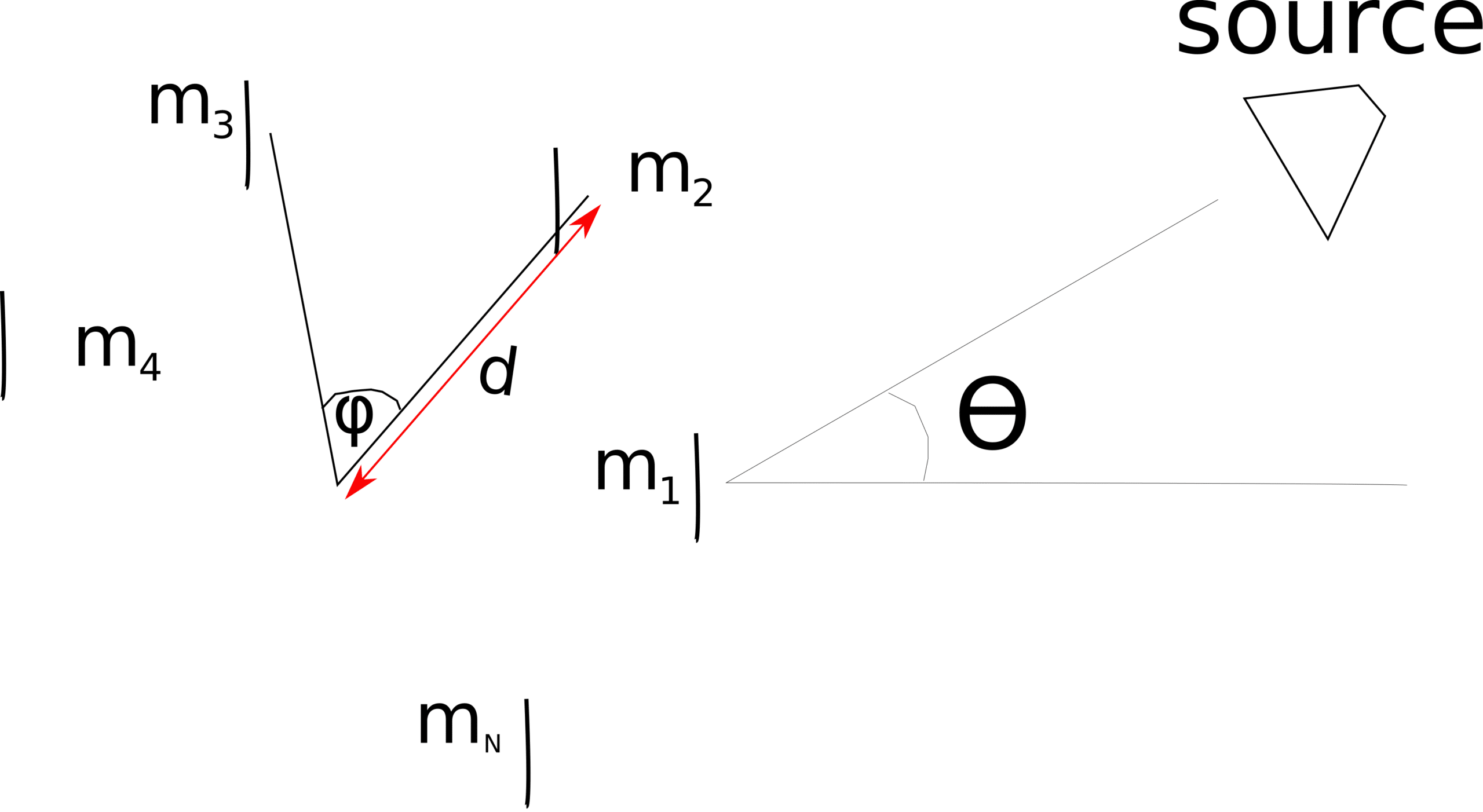
Figure 1: N UCA microphones
Suppose the signal at each microphone  is given as
is given as
 = s(w) e^{\left(-jw \frac{d}{c} \sin{\left((i-1)\psi - \theta\right)} \right)} + v_i(w)")
where ") is the desired speech signal,
is the desired speech signal,  is the direction of arrival (DOA) of the speech signal with respect to the normal to the axis joining all the microphones,
is the direction of arrival (DOA) of the speech signal with respect to the normal to the axis joining all the microphones, ") is the uncorrelated noise such that
is the uncorrelated noise such that ![\mathbb{E}[v_i(w) v_j^*(w)] = 0, i \neq j, \{i,j\} \in \{1, \cdots, N\}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bv_i%28w%29+v_j%5E%2A%28w%29%5D+%3D+0%2C+i+%5Cneq+j%2C+%5C%7Bi%2Cj%5C%7D+%5Cin+%5C%7B1%2C+%5Ccdots%2C+N%5C%7D&bg=ffffff&fg=000000&s=0 "\mathbb{E}[v_i(w) v_j^*(w)] = 0, i \neq j, \{i,j\} \in \{1, \cdots, N\}") and
and ![\mathbb{E}[ s(w) e^{\left(-jw \frac{d}{c} \sin{\left((i-1)\psi - \theta\right)} \right)} v_j^*(w)] = 0, \forall {i,j} \in \{1, \cdots, N\}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B+s%28w%29+e%5E%7B%5Cleft%28-jw+%5Cfrac%7Bd%7D%7Bc%7D+%5Csin%7B%5Cleft%28%28i-1%29%5Cpsi+-+%5Ctheta%5Cright%29%7D+%5Cright%29%7D+v_j%5E%2A%28w%29%5D+%3D+0%2C+%5Cforall+%7Bi%2Cj%7D+%5Cin+%5C%7B1%2C+%5Ccdots%2C+N%5C%7D&bg=ffffff&fg=000000&s=2 "\mathbb{E}[ s(w) e^{\left(-jw \frac{d}{c} \sin{\left((i-1)\psi - \theta\right)} \right)} v_j^*(w)] = 0, \forall {i,j} \in \{1, \cdots, N\}") .
.
The input SNR per frequency bin  , denoted
, denoted ") is given as
is given as
![iSNR = \frac{\mathbb{E}\left[|s(w)|^2 \right]}{\mathbb{E}\left[\left |v_1(w)\right|^2 \right]}](https://s0.wp.com/latex.php?latex=iSNR+%3D+%5Cfrac%7B%5Cmathbb%7BE%7D%5Cleft%5B%7Cs%28w%29%7C%5E2+%5Cright%5D%7D%7B%5Cmathbb%7BE%7D%5Cleft%5B%5Cleft+%7Cv_1%28w%29%5Cright%7C%5E2+%5Cright%5D%7D&bg=ffffff&fg=000000&s=2 "iSNR = \frac{\mathbb{E}\left[|s(w)|^2 \right]}{\mathbb{E}\left[\left |v_1(w)\right|^2 \right]}")
where ![\mathbb{E}[.]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B.%5D&bg=ffffff&fg=000000&s=0 "\mathbb{E}[.]") is the expectation operator.
is the expectation operator.
After the delay and sum beamformer, the output becomes:
 = s(w) + \frac{1}{N} \sum\limits_{n =0}^{N-1} v_{n+1}(w) e^{\left(jw \frac{d}{c} \sin{\left((n-1)\psi - \theta\right)} \right)}")
The output SNR per frequency bin , denoted ") is given as
is given as
![oSNR = \frac{\mathbb{E}\left[|s(w)|^2 \right]}{\mathbb{E}\left[\left | \frac{1}{N} \sum\limits_{n =0}^{N-1} v_{n+1}(w) e^{\left(jw \frac{d}{c} \sin{\left((n-1)\psi - \theta\right)} \right)} \right|^2 \right]}](https://s0.wp.com/latex.php?latex=oSNR+%3D+%5Cfrac%7B%5Cmathbb%7BE%7D%5Cleft%5B%7Cs%28w%29%7C%5E2+%5Cright%5D%7D%7B%5Cmathbb%7BE%7D%5Cleft%5B%5Cleft+%7C+%5Cfrac%7B1%7D%7BN%7D+%5Csum%5Climits_%7Bn+%3D0%7D%5E%7BN-1%7D+v_%7Bn%2B1%7D%28w%29+e%5E%7B%5Cleft%28jw+%5Cfrac%7Bd%7D%7Bc%7D+%5Csin%7B%5Cleft%28%28n-1%29%5Cpsi+-+%5Ctheta%5Cright%29%7D+%5Cright%29%7D+%5Cright%7C%5E2+%5Cright%5D%7D&bg=ffffff&fg=000000&s=2 "oSNR = \frac{\mathbb{E}\left[|s(w)|^2 \right]}{\mathbb{E}\left[\left | \frac{1}{N} \sum\limits_{n =0}^{N-1} v_{n+1}(w) e^{\left(jw \frac{d}{c} \sin{\left((n-1)\psi - \theta\right)} \right)} \right|^2 \right]}")
But
 e^{\left(jw \frac{d}{c} \sin{\left((n-1)\psi - \theta\right)} \right)}\right|^2 =\frac{1}{N^2} \sum\limits_{n =0}^{N-1} |v_{n+1}(w)|^2 + \frac{1}{N^2} \sum\limits_{n =1}^{N} \sum\limits_{m \neq n}^{N} v_{n}(w) v_{m}^*(w) e^{\left(jw\frac{d}{c} \left(\sin{((n-1)\psi-\theta)} -\sin{((m-1)\psi - \theta)} \right)\right)}")
Since by assumption ![\mathbb{E}[v_i(w) v_j^*(w)] = 0, i \neq j, \{i,j\} \in \{1, \cdots, N\}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bv_i%28w%29+v_j%5E%2A%28w%29%5D+%3D+0%2C+i+%5Cneq+j%2C+%5C%7Bi%2Cj%5C%7D+%5Cin+%5C%7B1%2C+%5Ccdots%2C+N%5C%7D&bg=ffffff&fg=000000&s=2 "\mathbb{E}[v_i(w) v_j^*(w)] = 0, i \neq j, \{i,j\} \in \{1, \cdots, N\}")
![\mathbb{E}\left[\left| \frac{1}{N} \sum\limits_{n =0}^{N-1} v_{n+1}(w) e^{\left(jw n \frac{d}{c} \sin{\theta} \right)} \right|^2\right] = \frac{\mathbb{E}[|v_1(w)|^2]}{N}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5B%5Cleft%7C+%5Cfrac%7B1%7D%7BN%7D+%5Csum%5Climits_%7Bn+%3D0%7D%5E%7BN-1%7D+v_%7Bn%2B1%7D%28w%29+e%5E%7B%5Cleft%28jw+n+%5Cfrac%7Bd%7D%7Bc%7D+%5Csin%7B%5Ctheta%7D+%5Cright%29%7D+%5Cright%7C%5E2%5Cright%5D+%3D+%5Cfrac%7B%5Cmathbb%7BE%7D%5B%7Cv_1%28w%29%7C%5E2%5D%7D%7BN%7D&bg=ffffff&fg=000000&s=2 "\mathbb{E}\left[\left| \frac{1}{N} \sum\limits_{n =0}^{N-1} v_{n+1}(w) e^{\left(jw n \frac{d}{c} \sin{\theta} \right)} \right|^2\right] = \frac{\mathbb{E}[|v_1(w)|^2]}{N}")
This leads to an oSNR of:
![oSNR = N \frac{\mathbb{E}\left[|s(w)|^2 \right]}{\mathbb{E}[|v_1(w)|^2]}](https://s0.wp.com/latex.php?latex=oSNR+%3D+N+%5Cfrac%7B%5Cmathbb%7BE%7D%5Cleft%5B%7Cs%28w%29%7C%5E2+%5Cright%5D%7D%7B%5Cmathbb%7BE%7D%5B%7Cv_1%28w%29%7C%5E2%5D%7D&bg=ffffff&fg=000000&s=2 "oSNR = N \frac{\mathbb{E}\left[|s(w)|^2 \right]}{\mathbb{E}[|v_1(w)|^2]}")
The SNR improvement, SNRI then becomes:

Thus, if  is increase by a factor of
is increase by a factor of  , the SNRI increases by a factor of
, the SNRI increases by a factor of  .
.
VOCAL Technologies offers custom designed solutions for beamforming with a robust voice activity detector, acoustic echo cancellation and noise suppression. Our custom implementations of such systems are meant to deliver optimum performance for your specific beamforming task. Contact us today to discuss your solution!