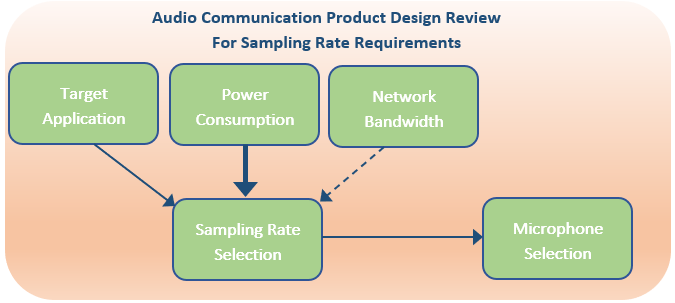
During the product design review phase of an audio communications product, one needs to determine what is the optimal sampling rate to use for said product. The first consideration is what type of audio sources are to be captured. If the audio source is music, then fullband (48kHz) sampling should be used. If the audio source is the human voice, then lower sampling rates can be used (8 to 16kHz), as there is very little speech intelligibility gain above 16kHz.
Another consideration is does the product have power consumption or computational complexity requirements. If product is to be used for low power applications, lower sampling rates shall be used. Especially, for full duplex speakerphone devices, which require acoustic echo cancellation. The computational complexity can be quite large for fullband sampling.
For the most part network bandwidth considerations are a nonfactor for modern communication channels. Even if network conditions become unstable and the data rate needs to be lowered, codecs such as Opus, provides the ability to temporary encode the audio at a lower sampling rate than the actual sampling rate. Therefore, no compromise needs to made in the audio layer design. However, if the product will be used with a low bandwidth network, then a lower sampling rate should be used to minimize power consumption.
It is not uncommon for MEMS microphones to have a divergent frequency response above 10kHz. Once the optimal sampling rate has been decided on for the product, one must verify the frequency response characteristics of the microphone can adequately support the chosen sampling rate.