Gauging the performance of a blind source separation (BSS) algorithm is non-trivial. It is obvious that the normal SNR improvement metrics will not suffice since there are multiple desired target signals. A metric that has gained traction over the recent decade is the signal to distortion ration, SDR.
To set up the problem, consider the system is illustrated in Figure 1 below.
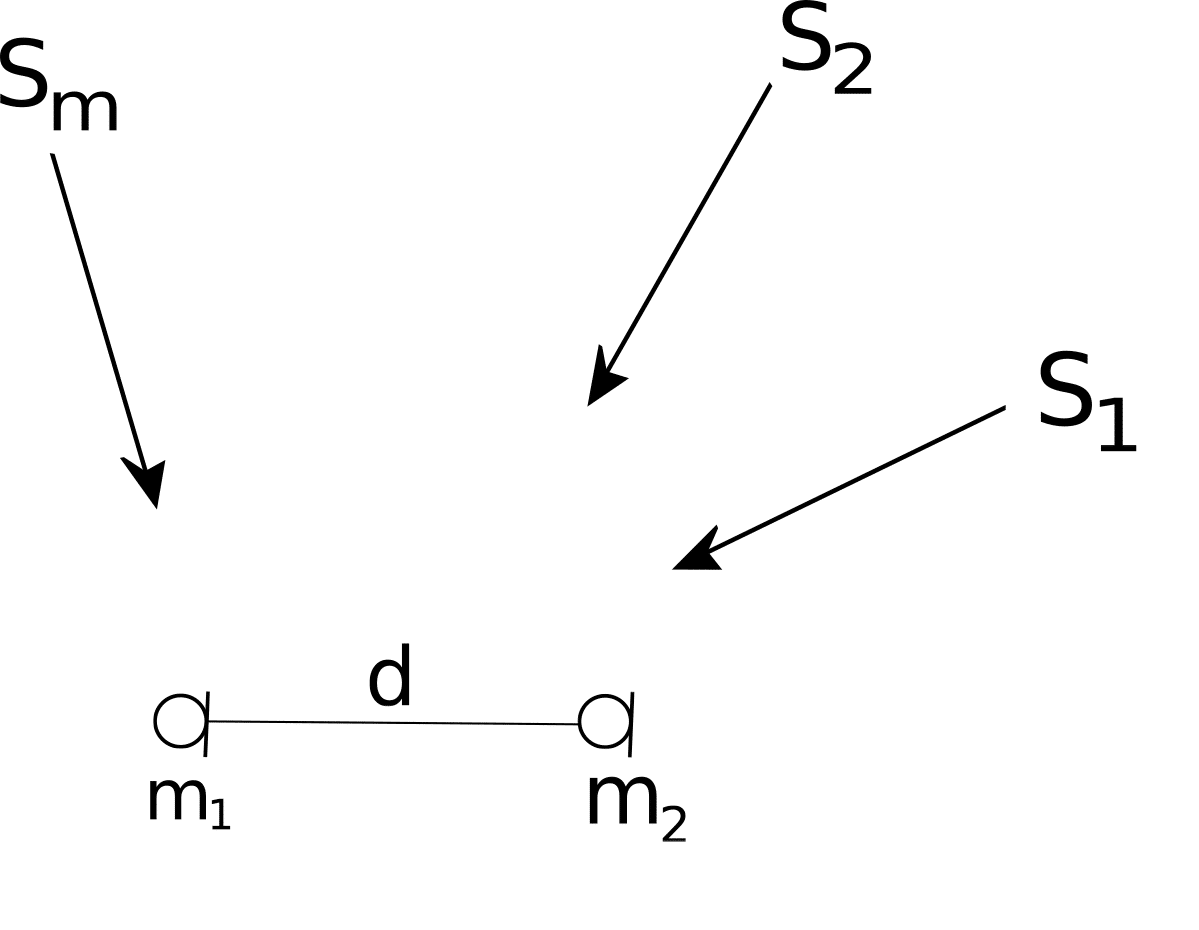
Figure 1: m source signals impinging 2 microphones
Now, suppose multiple algorithms are used to extract the desired target signals and it is required to rank the performance of such algorithms. Consider an extracted target
 = \alpha_k s_k(t,w) + \sum\limits_{i \neq k} \alpha_i s_i(t,w) +n_k(t,w) +D_k(t,w)")
where ") is the $k^{the}$ time-frequency desired signal,
is the $k^{the}$ time-frequency desired signal, ") the noise component in the extracted signal
the noise component in the extracted signal  and
and ") is the time-frequency distortion artifact in the desired signal. Based on the SNR concept, it is intuitive to define the so-called SDR as
is the time-frequency distortion artifact in the desired signal. Based on the SNR concept, it is intuitive to define the so-called SDR as
 = \frac{\alpha_k s_k(t,w)}{ \sum\limits_{i \neq k} \alpha_i s_i(t,w) +n_k(t,w) +D_k(t,w)}")
Suppose the mixing matrix is a time invariant gain, then the temporal dependency can be dropped to get
 = \frac{\alpha_k s_k(w)}{ \sum\limits_{i \neq k} \alpha_i s_i(w) +n_k(w) +D_k(w)}")
To be able to actualize this metric, the extracted signals have to be decomposed. Almost all BSS algorithms make the explicit assumption that the target signals are statistically independent. The target signals in the mixture, in the absence of noise can be decomposed by orthogonal projections to span the subspace  . Denote
. Denote } := W^\perp(s_k(w))") where
where )") is the orthogonal subspace projector. Then clearly
is the orthogonal subspace projector. Then clearly
} := W^\perp(\alpha_k s_k(w))")
\}|_{i \neq k}} := W^\perp(\{\alpha_i s_i(w)\}|_{i \neq k})")
The use of inner products is then utilized to compute the SDR.
As a custom design house, VOCAL Technologies offers custom designed solutions for blind signal separation with a robust voice activity detector, acoustic echo cancellation and noise suppression. Our custom implementations of such systems are meant to deliver optimum performance for your specific task. Contact us today to discuss your solution!