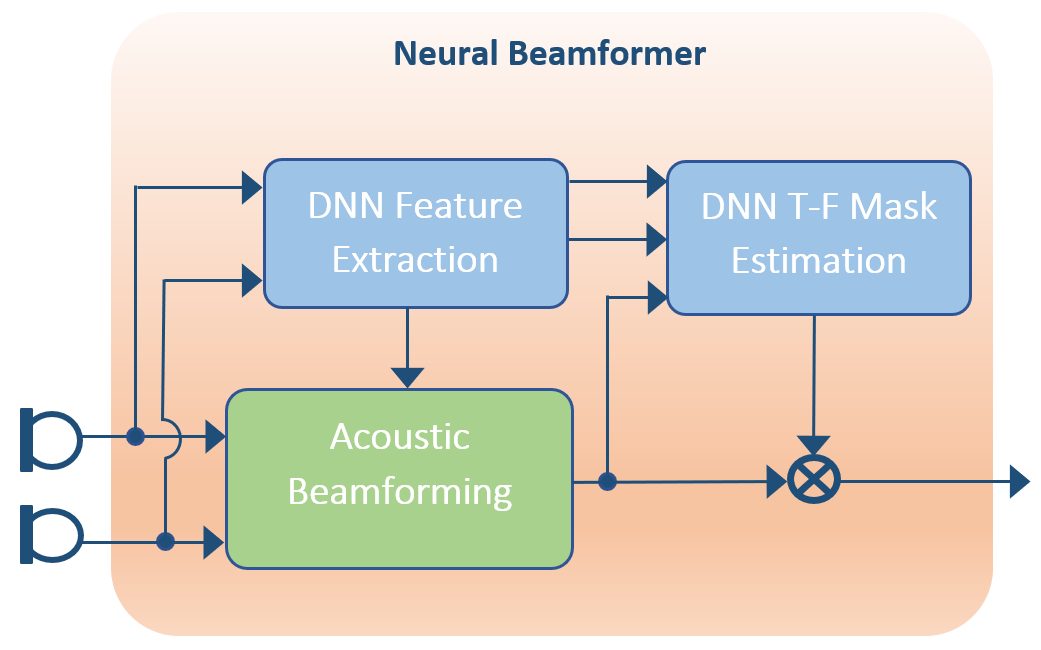
Deep Neural Networks are beneficial to traditional beamforming solutions, either by cleaning up the multi-microphone inputs prior to beamforming or by post-processing the beamforming output. DNNs also can be used to generate the optimal beamforming weights. Many classical adaptive beamformers, such as MVDR, use the estimated spatial covariance matrix to derive the beamforming weights based on a given optimization criteria. DNN beamformers or neural beamformers have weights generated by a DNN model that is a trained based on the loss function and a set of input features.
One of the challenges of Neural Networks is that they can too often be viewed as a black box. Most systems are trained to produce a clean speech signal or to minimize the word error rate of an automatic speech recognition engine. There is no guarantee that the DNN generated beamforming weights are maximizing the spatial filtering capabilities. Microphone arrays provide information spatial information on the acoustic scene that a single microphone cannot capture. Therefore, the selection of the input features is important to a neural beamformer. One promising solution is to use a network to estimate the spatial covariance matrix to determine the optimal MVDR beamforming weights. Then when for a given frame, if the spatial cues are noisy or considered unreliable, the network can use spectral features to separate the sound sources, in the same vein as single channel noise reduction. This combination of spatial and spectral information provides speech enhancement across a variety of scenarios.