Typical algorithms for acoustic echo cancellation (AEC) are the LMS and NLMS algorithms for their ease of implementation and relatively fast convergence rates, especially for real time implementations. The filter taps obtained from the NLMS, and by extension the LMS algorithm, is however not the maximum likelihood estimate. We derive the maximum likelihood estimate and compare to the NLMS and the LMS algorithms. Consider the systems depicted in Figure 1 below:
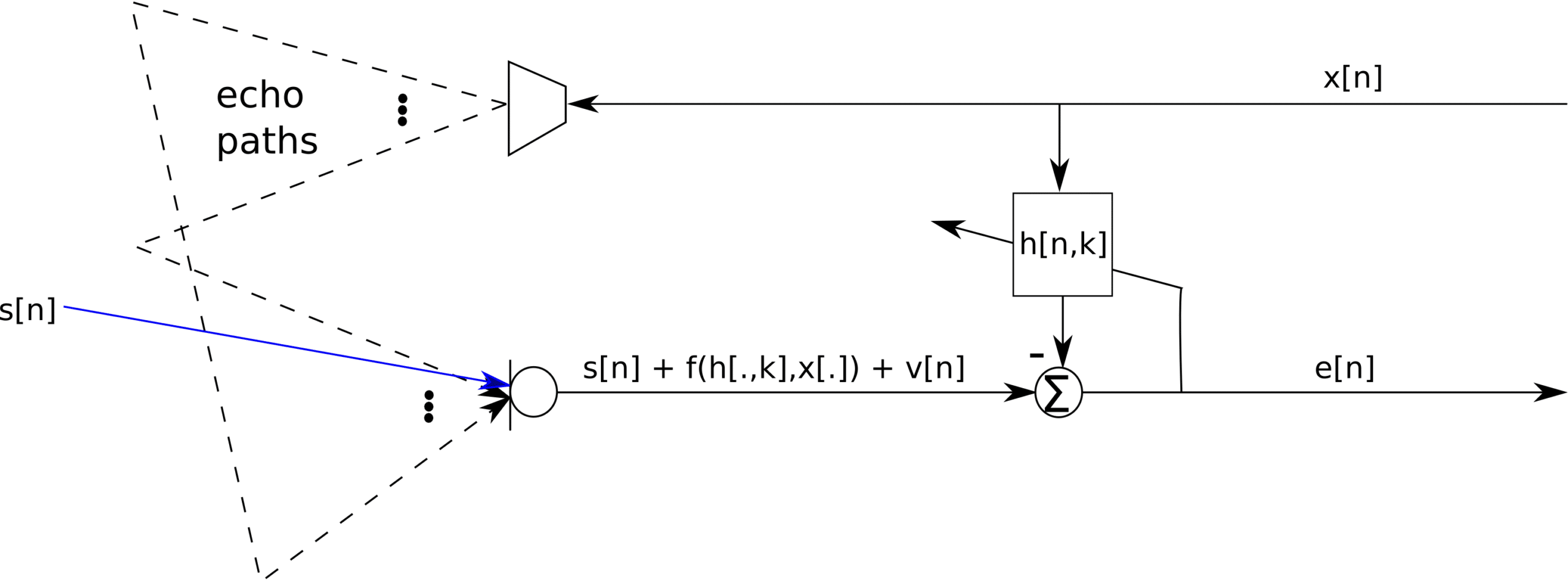
Figure 1: Single line AEC architecture
The problem at hand is to correctly estimate the filter taps, such that ![f(h[.],x[.]) = \sum\limits_{i=1}^M h[i]x[k-i]](https://s0.wp.com/latex.php?latex=f%28h%5B.%5D%2Cx%5B.%5D%29+%3D+%5Csum%5Climits_%7Bi%3D1%7D%5EM+h%5Bi%5Dx%5Bk-i%5D&bg=ffffff&fg=000000&s=0 "f(h[.],x[.]) = \sum\limits_{i=1}^M h[i]x[k-i]") , to minimize the error. The presence of the signal
, to minimize the error. The presence of the signal ![s[n]](https://s0.wp.com/latex.php?latex=s%5Bn%5D&bg=ffffff&fg=000000&s=0 "s[n]") may cause the adaptive system to cancel out the speech signal, thus leading most AECs updating the filter coefficients only when there is no speech detected. Now consider a received signal
may cause the adaptive system to cancel out the speech signal, thus leading most AECs updating the filter coefficients only when there is no speech detected. Now consider a received signal
![r[k] = \sum\limits_{i=1}^M h[i]x[k-i] + v[k]](https://s0.wp.com/latex.php?latex=r%5Bk%5D+%3D+%5Csum%5Climits_%7Bi%3D1%7D%5EM+h%5Bi%5Dx%5Bk-i%5D+%2B+v%5Bk%5D&bg=ffffff&fg=000000&s=0 "r[k] = \sum\limits_{i=1}^M h[i]x[k-i] + v[k]")
where ![v[k]](https://s0.wp.com/latex.php?latex=v%5Bk%5D&bg=ffffff&fg=000000&s=0 "v[k]") is additive noise. Also consider that
is additive noise. Also consider that ![x[k-i], \forall i \in \{1, \cdots, M\}, \forall k](https://s0.wp.com/latex.php?latex=x%5Bk-i%5D%2C+%5Cforall+i+%5Cin+%5C%7B1%2C+%5Ccdots%2C+M%5C%7D%2C+%5Cforall+k&bg=ffffff&fg=000000&s=0 "x[k-i], \forall i \in \{1, \cdots, M\}, \forall k") is known. We want to estimate
is known. We want to estimate ![\hat{h}[i], \forall i \in \{1, \cdots, M\}](https://s0.wp.com/latex.php?latex=%5Chat%7Bh%7D%5Bi%5D%2C+%5Cforall+i+%5Cin+%5C%7B1%2C+%5Ccdots%2C+M%5C%7D&bg=ffffff&fg=000000&s=0 "\hat{h}[i], \forall i \in \{1, \cdots, M\}") such that
such that ![|e[n]|^2](https://s0.wp.com/latex.php?latex=%7Ce%5Bn%5D%7C%5E2&bg=ffffff&fg=000000&s=0 "|e[n]|^2") is minimized, where
is minimized, where
![e[n] = \sum\limits_{i=1}^M (h[i]-\hat{h}[i])x[n-i] + v[n]](https://s0.wp.com/latex.php?latex=e%5Bn%5D+%3D+%5Csum%5Climits_%7Bi%3D1%7D%5EM+%28h%5Bi%5D-%5Chat%7Bh%7D%5Bi%5D%29x%5Bn-i%5D+%2B+v%5Bn%5D&bg=ffffff&fg=000000&s=0 "e[n] = \sum\limits_{i=1}^M (h[i]-\hat{h}[i])x[n-i] + v[n]")
Consider the noise signal being i.i.d. Gaussian, then the likelihood function, the joint pdf, for a frame of length N can be given as
![f_{{\bf r}|{\bf h}}({\bf r}|{\bf h}) = \prod\limits_{k=1}^N \frac{1}{\sqrt{2\pi \sigma_{r_k}}} e^{-\frac{\left(r_k-\sum\limits_{m=1}^M h[m]x[k-m] \right)^2}{\sigma_{r_k}^2}}](https://s0.wp.com/latex.php?latex=f_%7B%7B%5Cbf+r%7D%7C%7B%5Cbf+h%7D%7D%28%7B%5Cbf+r%7D%7C%7B%5Cbf+h%7D%29+%3D+%5Cprod%5Climits_%7Bk%3D1%7D%5EN+%5Cfrac%7B1%7D%7B%5Csqrt%7B2%5Cpi+%5Csigma_%7Br_k%7D%7D%7D+e%5E%7B-%5Cfrac%7B%5Cleft%28r_k-%5Csum%5Climits_%7Bm%3D1%7D%5EM+h%5Bm%5Dx%5Bk-m%5D+%5Cright%29%5E2%7D%7B%5Csigma_%7Br_k%7D%5E2%7D%7D&bg=ffffff&fg=000000&s=0 "f_{{\bf r}|{\bf h}}({\bf r}|{\bf h}) = \prod\limits_{k=1}^N \frac{1}{\sqrt{2\pi \sigma_{r_k}}} e^{-\frac{\left(r_k-\sum\limits_{m=1}^M h[m]x[k-m] \right)^2}{\sigma_{r_k}^2}}")
where ![{\bf r}= [r[1], \cdots,r[N]]^T](https://s0.wp.com/latex.php?latex=%7B%5Cbf+r%7D%3D+%5Br%5B1%5D%2C+%5Ccdots%2Cr%5BN%5D%5D%5ET&bg=ffffff&fg=000000&s=0 "{\bf r}= [r[1], \cdots,r[N]]^T") ,
, ![{\bf h}= [h[1], \cdots,h[M]]^T](https://s0.wp.com/latex.php?latex=%7B%5Cbf+h%7D%3D+%5Bh%5B1%5D%2C+%5Ccdots%2Ch%5BM%5D%5D%5ET&bg=ffffff&fg=000000&s=0 "{\bf h}= [h[1], \cdots,h[M]]^T") and
and  . The log-likelihood function then becomes
. The log-likelihood function then becomes
![L({\bf r}|{\bf h}) =\kappa -\sum\limits_{k=1}^N \left(\frac{1}{4} \log{\sigma_{v_k}^2} +\frac{\left(r_k-\sum\limits_{m=1}^M h[m]x[k-m] \right)^2}{\sigma_{v_k}^2} \right)](https://s0.wp.com/latex.php?latex=L%28%7B%5Cbf+r%7D%7C%7B%5Cbf+h%7D%29+%3D%5Ckappa+-%5Csum%5Climits_%7Bk%3D1%7D%5EN+%5Cleft%28%5Cfrac%7B1%7D%7B4%7D+%5Clog%7B%5Csigma_%7Bv_k%7D%5E2%7D+%2B%5Cfrac%7B%5Cleft%28r_k-%5Csum%5Climits_%7Bm%3D1%7D%5EM+h%5Bm%5Dx%5Bk-m%5D+%5Cright%29%5E2%7D%7B%5Csigma_%7Bv_k%7D%5E2%7D+%5Cright%29&bg=ffffff&fg=000000&s=0 "L({\bf r}|{\bf h}) =\kappa -\sum\limits_{k=1}^N \left(\frac{1}{4} \log{\sigma_{v_k}^2} +\frac{\left(r_k-\sum\limits_{m=1}^M h[m]x[k-m] \right)^2}{\sigma_{v_k}^2} \right)")
where  is a constant term. The maximum value of the log-likelihood function will obey:
is a constant term. The maximum value of the log-likelihood function will obey:
![\sum\limits_{k=1}^N \frac{2}{\sigma_{v_k}^2} \left(r_k-\sum\limits_{m=1}^M h[m]x[k-m] \right) x[k-q] =0 , q \in \{1,\cdots,M\}](https://s0.wp.com/latex.php?latex=%5Csum%5Climits_%7Bk%3D1%7D%5EN+%5Cfrac%7B2%7D%7B%5Csigma_%7Bv_k%7D%5E2%7D+%5Cleft%28r_k-%5Csum%5Climits_%7Bm%3D1%7D%5EM+h%5Bm%5Dx%5Bk-m%5D+%5Cright%29+x%5Bk-q%5D+%3D0+%2C+q+%5Cin+%5C%7B1%2C%5Ccdots%2CM%5C%7D&bg=ffffff&fg=000000&s=0 "\sum\limits_{k=1}^N \frac{2}{\sigma_{v_k}^2} \left(r_k-\sum\limits_{m=1}^M h[m]x[k-m] \right) x[k-q] =0 , q \in \{1,\cdots,M\}")
Thus the ML algorithm will proceed as:
![\hat{h}[i]_{n+1} = \hat{h}[i]_{n} + \mu_i \sum\limits_{k=1}^N \frac{2}{\sigma_{v_k}^2} \left(r_k-\sum\limits_{m=1}^M h[m]x[k-m] \right) x[k-i]](https://s0.wp.com/latex.php?latex=%5Chat%7Bh%7D%5Bi%5D_%7Bn%2B1%7D+%3D+%5Chat%7Bh%7D%5Bi%5D_%7Bn%7D+%2B+%5Cmu_i+%5Csum%5Climits_%7Bk%3D1%7D%5EN+%5Cfrac%7B2%7D%7B%5Csigma_%7Bv_k%7D%5E2%7D+%5Cleft%28r_k-%5Csum%5Climits_%7Bm%3D1%7D%5EM+h%5Bm%5Dx%5Bk-m%5D+%5Cright%29+x%5Bk-i%5D&bg=ffffff&fg=000000&s=0 "\hat{h}[i]_{n+1} = \hat{h}[i]_{n} + \mu_i \sum\limits_{k=1}^N \frac{2}{\sigma_{v_k}^2} \left(r_k-\sum\limits_{m=1}^M h[m]x[k-m] \right) x[k-i]")
Comparing the ML update equation to the NLMS algorithm update which is reproduced below,
![\hat{h}[i]_{n+1} = \hat{h}[i]_{n} + \sum\limits_{k=1}^N \left(\frac{1}{\sum\limits_{m=1}^M x[k-m+1]^2 } \left(r_k -\sum\limits_{m=1}^M \hat{h}[m]_{n} x[k-m+1]\right) x[k-i] \right)](https://s0.wp.com/latex.php?latex=%5Chat%7Bh%7D%5Bi%5D_%7Bn%2B1%7D+%3D+%5Chat%7Bh%7D%5Bi%5D_%7Bn%7D+%2B+%5Csum%5Climits_%7Bk%3D1%7D%5EN+%5Cleft%28%5Cfrac%7B1%7D%7B%5Csum%5Climits_%7Bm%3D1%7D%5EM+x%5Bk-m%2B1%5D%5E2+%7D+%5Cleft%28r_k+-%5Csum%5Climits_%7Bm%3D1%7D%5EM+%5Chat%7Bh%7D%5Bm%5D_%7Bn%7D+x%5Bk-m%2B1%5D%5Cright%29+x%5Bk-i%5D+%5Cright%29&bg=ffffff&fg=000000&s=0 "\hat{h}[i]_{n+1} = \hat{h}[i]_{n} + \sum\limits_{k=1}^N \left(\frac{1}{\sum\limits_{m=1}^M x[k-m+1]^2 } \left(r_k -\sum\limits_{m=1}^M \hat{h}[m]_{n} x[k-m+1]\right) x[k-i] \right)")
it can be seen that there is a change of ![\frac{1}{\sum\limits_{m=1}^M x[k-m+1]^2 }](https://s0.wp.com/latex.php?latex=%5Cfrac%7B1%7D%7B%5Csum%5Climits_%7Bm%3D1%7D%5EM+x%5Bk-m%2B1%5D%5E2+%7D&bg=ffffff&fg=000000&s=0 "\frac{1}{\sum\limits_{m=1}^M x[k-m+1]^2 }") to
to  and a reintroduction of the step size
and a reintroduction of the step size  . The popularity of the NLMS is precisely because of the availability of . However, given a frame size of length
. The popularity of the NLMS is precisely because of the availability of . However, given a frame size of length  , the variance of the noise could easily be estimated. Notice that the variance of the noise is the same as that of the recorded signal
, the variance of the noise could easily be estimated. Notice that the variance of the noise is the same as that of the recorded signal  and if given that is zero mean, then the variance can be estimated directly from . A sample result for this algorithm is shown in Figure 2 below with comparison with the NLMS algorithm.
and if given that is zero mean, then the variance can be estimated directly from . A sample result for this algorithm is shown in Figure 2 below with comparison with the NLMS algorithm.

Figure 2: Performance of ML AEC
VOCAL Technologies offers custom designed solutions for beamforming with a robust voice activity detector, acoustic echo cancellation and noise suppression. Our custom implementations of such systems are meant to deliver optimum performance for your specific beamforming task. Contact us today to discuss your solution!