The effectiveness of Deep Neural Networks at improving the speech intelligibility of noisy signals has made them an attractive solution. However, in order to achieve the quality and generalization needed for unmatched noise conditions of real-world applications, the number of required layers and nodes can be high. The computational complexity and memory size of DNNs is one the major roadblocks in having DNN speech enhancement algorithms more commonly implemented in real-time communication systems.
Some of the most popular approaches to optimizing deep neural networks are:
- Quantization – reducing the number of bits needed to represent a node.
- Fine Grain (unstructured) Pruning – removing a number of trainable parameters by eliminating those with small weights.
- Coarse Gain (structured) Pruning – removes a layer by evaluating the weight as a group.
- Tensor decomposition – decompose a large weight tensor into multiple smaller tensors by using a low rankness
- Knowledge Distillation – using the output of a larger network to train a smaller network
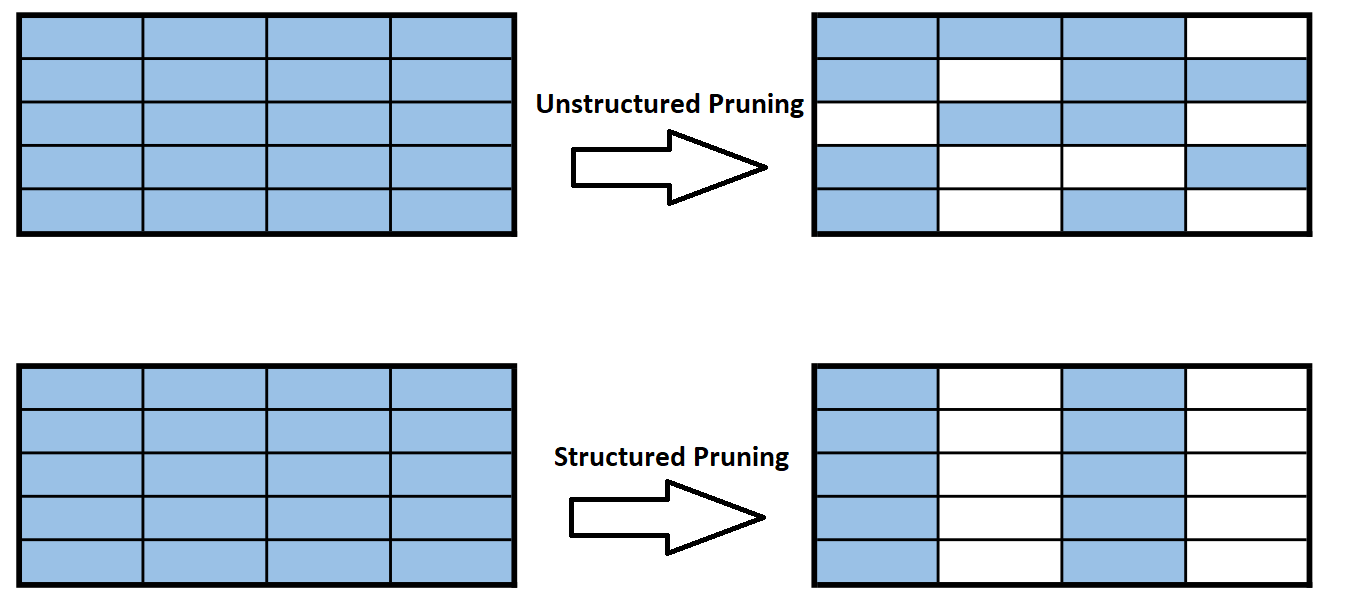
All of these methods that advantage of the fact the neural networks tend to contain redundant and excessive information. This level of optimization should be performed as one of the final stages of an algorithm. Before starting to optimize an existing model with one of the above techniques, one should must take into consideration the structure of the NN and whether it best matches the task at hand.