The challenge of wideband acoustic beamforming is the directivity of the microphone array is frequency dependent. For acoustic beamforming for speech applications, the target frequency range is typically from 200 to 8000Hz. With Delay-and-Sum beamforming, a large interelement spacing of a microphone array is required to get better directivity. The Superdirective Beamformer (SDBF) was developed to help overcome this limitation of delay-and-sum beamforming.
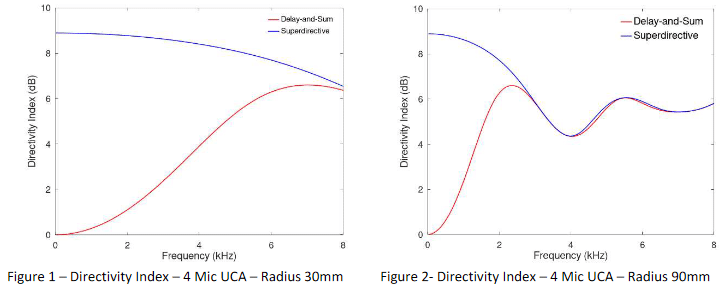
As shown in Figures 1 and 2, the SDBF clearly has better spatial selectivity at lower frequencies as compared to the Delay-and-Sum Beamformer. However, this improvement in directivity comes at a cost. The Superdirective Beamformer is the optimal beamforming solution for a spherically isotropic noise field, but for an uncorrelated noise field the SDBF amplifies the noise. It turns out that the delay-and-sum beamformer is the optimal beamforming solution in an uncorrelated noise field.
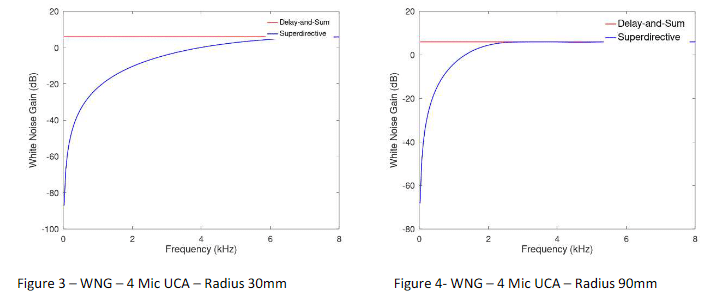
Figures 3 and 4, show the frequency dependent white noise gain (WNG) of SDBFs. This illustrates the tradeoff between directivity and WNG. In practice, the microphone signal contains a combination of the directional and uncorrelated noise fields. Therefore, a compromise between the delay-and-sum beamformer and superdirective beamformer needs to be reached to obtain the optimal solution. The equation of the SDBF as follows:
}\ \boldsymbol{d})/(\boldsymbol{d}^H\ \boldsymbol{\Gamma}^{(-1)}\ \boldsymbol{d})")
Where d is the steering vector, and Γ is the coherence matrix of the noise field. The coherence function of the spherically isotropic noise field is the sinc function. A frequency dependent scaling factor can be added to the diagonal elements of the coherence matrix. The scaling factor is a ratio of the estimated sensor noise power to ambient noise power.
VOCAL Technologies offers custom designed solutions for beamforming with a robust voice activity detector, acoustic echo cancellation and noise suppression. Our custom implementations of such systems are meant to deliver optimum performance for your specific beamforming task.