A metric that is used in quantifying the performance of a beamforming algorithm is the is the ability to suppress spatially uncorrelated noise. This normally comes from the quality of the microphones which are deployed due to the electric self noise that is generated. The technical term for this quantity is the white noise gain. The design of any beamformer should have the white noise gain in mind since amplifying white noise will negate any improvements gained from amplifying the desired signal with the use of multiple microphones.
Consider the microphone array as shown in Figure 1:
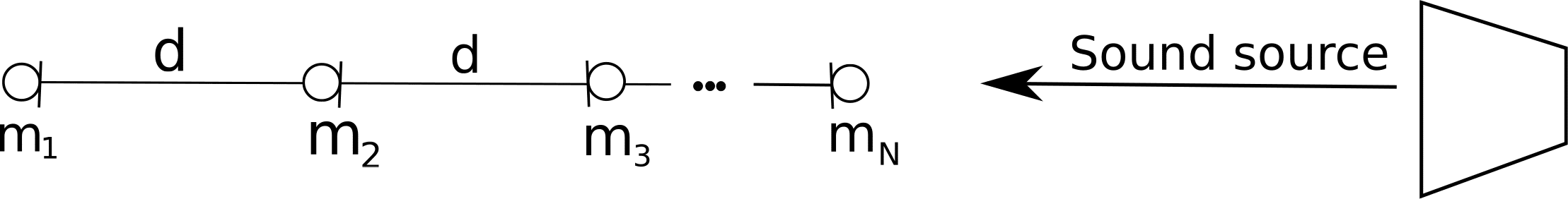
Figure 1: N microphone array
The signal received at each microphone can be denoted in the time frequency domain as
 = s(t,w) e^{-j\omega\tau_i} + v_i(t,w)")
where ") is the recorded signal at microphone
is the recorded signal at microphone  ,
, ") is the desired signal, and
is the desired signal, and ") is the noise at microphone . All the microphone signals can be cascaded in matrix notation such that
is the noise at microphone . All the microphone signals can be cascaded in matrix notation such that
 = s(t,w) {\bf d}(\omega,\tau_1, \cdots, \tau_N) + {\bf v}(t,w)")
with ![{\bf X}(t, \omega) = [x_1(t, \omega), \cdots, x_N(t, \omega)]^T](https://s0.wp.com/latex.php?latex=%7B%5Cbf+X%7D%28t%2C+%5Comega%29+%3D+%5Bx_1%28t%2C+%5Comega%29%2C+%5Ccdots%2C+x_N%28t%2C+%5Comega%29%5D%5ET&bg=ffffff&fg=000000&s=0 "{\bf X}(t, \omega) = [x_1(t, \omega), \cdots, x_N(t, \omega)]^T") ,
, ![{\bf d}(\omega,\tau_1, \cdots, \tau_N) = [e^{-j\omega\tau_1}, \cdots, e^{-j\omega\tau_N}]^T](https://s0.wp.com/latex.php?latex=%7B%5Cbf+d%7D%28%5Comega%2C%5Ctau_1%2C+%5Ccdots%2C+%5Ctau_N%29+%3D+%5Be%5E%7B-j%5Comega%5Ctau_1%7D%2C+%5Ccdots%2C+e%5E%7B-j%5Comega%5Ctau_N%7D%5D%5ET&bg=ffffff&fg=000000&s=0 "{\bf d}(\omega,\tau_1, \cdots, \tau_N) = [e^{-j\omega\tau_1}, \cdots, e^{-j\omega\tau_N}]^T") and
and ![{\bf v}(t, \omega) = [v_1(t, \omega), \cdots, v_N(t, \omega)]^T](https://s0.wp.com/latex.php?latex=%7B%5Cbf+v%7D%28t%2C+%5Comega%29+%3D+%5Bv_1%28t%2C+%5Comega%29%2C+%5Ccdots%2C+v_N%28t%2C+%5Comega%29%5D%5ET&bg=ffffff&fg=000000&s=0 "{\bf v}(t, \omega) = [v_1(t, \omega), \cdots, v_N(t, \omega)]^T") . Now, suppose and estimate of the steering vector
. Now, suppose and estimate of the steering vector ") denoted
denoted ") is returned by an algorithm, them the output signal mow becomes
is returned by an algorithm, them the output signal mow becomes
 = {\bf W}^H (\omega,\tau_1, \cdots, \tau_N) {\bf X}(t, \omega)")
The output power spectral density, PSD, then becomes:
 y(t,\omega)} = {\bf W}^H (\omega,\tau_1, \cdots, \tau_N) \Phi_{{\bf X}(t,\omega) {\bf X}(t,\omega)} {\bf W} (\omega,\tau_1, \cdots, \tau_N)")
In the noise free case, the PSD becomes:
 y(t,\omega)} |_{{\text signal}} = |s(t,w)|^2{\bf W}^H (\omega,\tau_1, \cdots, \tau_N) \Phi_{{\bf d}(\omega,\tau_1, \cdots, \tau_N) {\bf d}(\omega,\tau_1, \cdots, \tau_N) } {\bf W} (\omega,\tau_1, \cdots, \tau_N)")
Similarly, in the signal free case, the PSD becomes:
 y(t,\omega)} |_{{\text noise}} = {\bf W}^H (\omega,\tau_1, \cdots, \tau_N) \Phi_{{\bf v}(t,w) {\bf v}(t,w) } {\bf W} (\omega,\tau_1, \cdots, \tau_N)")
The white noise gain is the SNR for a unit variance uncorrelated noise, which implies that the expectation of the noise PSD becomes:
 y(t,\omega)} |_{{\text white~noise}} = {\bf W}^H (\omega,\tau_1, \cdots, \tau_N) {\bf W} (\omega,\tau_1, \cdots, \tau_N) = N")
Thus, the white noise gain is given as:
 = \frac{|s(t,w)|^2 |{\bf W}^H (\omega,\tau_1, \cdots, \tau_N) {\bf d}(\omega,\tau_1, \cdots, \tau_N)|^2}{ N}")
It should be noted that for non-line audio signals, there are also ambient white noise, hence the noise coherence may not be identity. The final beamforming algorithm design should factor in all these scenarios.
VOCAL Technologies offers custom designed solutions for beamforming with a robust voice activity detector, acoustic echo cancellation and noise suppression. Our custom implementations of such systems are meant to deliver optimum performance for your specific beamforming task. Contact us today to discuss your solution!