A microphone array, if properly designed, has the capability to provide varying gains in different directions in space. We call this feature as spatially selectiveness of a microphone array.
With the spatial selective feature, a microphone array can enhance a desired target sound that travels in a direction, or suppress an interfering source from a different direction. Of course, if both the desired sound and the interfering sound come from the same direction, then the microphone array does not have the ability to differentiate.
As discussed in many of the published literatures, the direction of the desired target sound source is usually assumed known as a priori. However this condition is really satisfied in practice. We discuss in this short article a solution when the target sound source is not known.
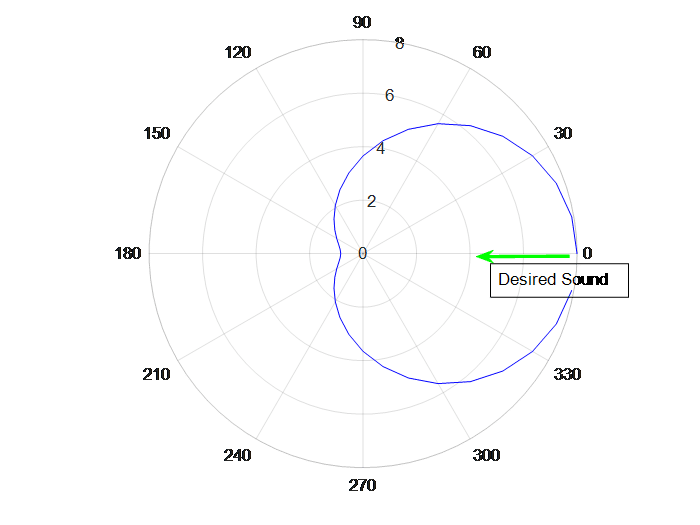
As shown in the following diagram, the desired sound is travelling from the 0 degree angle. Ideally we would want to form a heart shaped beam pattern as shown in blue. It maximizes the directional gain at the incoming direction of the desired sound.
Since we assume no knowledge of the desired sound, we have to formulate it into a power optimization problem with a constraint on the beam forming vector w as below.
![{maxE}\left[\left|{y}\left(t\right)\right|^2\right]](https://s0.wp.com/latex.php?latex=%7BmaxE%7D%5Cleft%5B%5Cleft%7C%7By%7D%5Cleft%28t%5Cright%29%5Cright%7C%5E2%5Cright%5D&bg=ffffff&fg=000000&s=0 "{maxE}\left[\left|{y}\left(t\right)\right|^2\right]")

where =\sum_{m=1}^{M}{w_m\ast x_m\left(t\right)}") .
.
The constraint forces the solution to be within a finite range. When a single sound a sound is present, the solution yields the optimum beam pattern with maximum gain towards the target direction. If the target dynamically changes locations, such as, in the case that the sound source is a talker who walks around the microphone array in a circle, the algorithm will automatically follow and steer the maximum gain toward the talk location.
The main drawback with the algorithm is that it depends on a reliable double talk detector. It will not work correctly when interference or competing sound sources are present. We will address this problem in a separate article.